
Papierloses Büro bedeutet zu einem großen Teil, dass Dokumente archiviert und wiedergefunden werden wollen und das natürlich ohne echtes Papier. Viele der Dokumente braucht man auch nie wieder. Aber spätestens bei der nächsten Steuererklärung muss doch wieder alles Mögliche an alten Rechnungen und Bank-Dokumenten herausgezogen werden. Viel Spaß macht das Thema nicht.
Dies klassisch über eine Ordnerstruktur zu machen ist zunächst naheliegend. Dank OCRmyPDF und Recoll ist ein Wiederfinden möglich. Und dank Python-Organize ist das automatische einsortieren in die Ordnerstruktur möglich und weitere kleine Scripte und Schritte sorgen für Ordnung. Artikel hierzu findet ihr im Blog.
Aber es bleiben eben trotzdem viele einzelne Schritte. Und bei vielen einzelnen Schritten gibt es viele kleine Stellen, an denen etwas schief gehen kann und bei denen man Zeit verliert. Also warum keine gesamtheitliche Lösung einsetzen?
Da meine Banken ein sehr hohes Mitteilungsbedürfnis haben, komme ich, obwohl ich nur in einem normalen Angestelltenverhältnis bin, auf circa 1000 Dokumente pro Jahr. Also musste etwas Besseres als eine einfache Ordnerstruktur her: Paperless-ng.
Voraussetzungen
Grundsätzlich erfüllt eine Dokumentenverwaltung zwei Aufgaben: Dokumente abspeichern. Dokumente wiederfinden.
Die Details sind dann schon ein wenig komplizierter.
Meine Anforderungen an ein System zur Dokumentenverwaltung sind gar nicht viele, aber die haben es in sich:
- Intuitives UI
- Automatische Sortierung in Ordner / Zuordnung von Tags
- OCR
- Original-Daten nicht in Datenbank "gefangen"
- Exit-Strategie
- Single-User ausreichend
- Fokus auf PDF-Dateien
- Akzeptabler Aufwand für Installation und Pflege
- Keine Cloud Lösung
Mir ist besonders der Punkt wichtig, dass die Dokumente in keiner Datenbank "gefangen" sind. Denn dies würde voraussetzen, dass das Dokumentenverwaltungssystem laufen muss, damit ich auf die Dokumente zugreifen kann. Was ist im Notfall? Die Software startet nicht mehr, weil irgendein Update die Datenbank beschädigt hat? Oder einfach nur, weil der Docker-Daeamon nicht mehr mag. Klar, mit einem guten Backup, sollte dies alles in den Griff zu bekommen sein, aber man weiß ja nicht. Also sollten die Original-Dokumente möglichst "nackt" im Dateisystem liegen. Eine Verarbeitung in der Cloud wäre sicher das bequemste, aber kommt für mich aus Datenschutzgründen nicht in Frage.
Paperless-ng
Ich bin bereits öfter über das Projekt Paperless gestolpert. Allerdings konnte ich mich damit nie wirklich anfreunden. Zudem ist die Entwicklung abgeschlossen und das Repository mittlerweile archiviert. Durch Zufall bin ich dann vor einiger Zeit auf Paperless-ng gestoßen, was ein Fork von Paperless ist und noch sehr aktiv weiterentwickelt wird. Paperless-ng erfüllt alle genannten Anforderungen und sogar noch einiges mehr.
Die Installation und Konfiguration
Die Installation ist für jeden, der schon ein wenig Erfahrungen mit Docker hat, einfach:
Das docker-compose.postgres.yml von github herunterladen und unter docker-compose.yml speichern.
Und nun noch das docker-compose.env von github herunterladen und daneben ablegen. In diesem File wird die Konfiguration durchgeführt. Es sind nur ein paar wenige Änderungen notwendig:
-
Die korrekte Zeitzone setzen:
PAPERLESS_TIME_ZONE=Europe/Berlin -
Die korrekte Sprache für OCR setzten:
PAPERLESS_OCR_LANGUAGE=deu -
Und nun noch die Ordnerstruktur festlegen:
PAPERLESS_FILENAME_FORMAT={created_year}/{correspondent}/{title}
Die letzte Einstellung legt fest, wie die PDF-Dateien im Dateisystem abgelegt werden sollen. In diesem Fall z.B.
2020/HypoVereinsbank/Kontoauszug_Januar.pdf
Details zu den Optionen sind in der Dokumentation zu finden.
Würde die letzte Option nicht gesetzt werden, würden alle Dateien nur flach in einem Verzeichnis mit einer eindeutigen ID liegen. Nicht sehr übersichtlich. Mit der oben gezeigten Änderung können Dokumente bei Bedarf auch ohne ein lauffähiges Paperless-ng im Dateisystem wiedergefunden werden.
Und schon kann Paperless-ng gestartet werden:
docker-compose up -d
Damit wir uns einloggen können, muss nun noch ein User angelegt werden:
docker-compose run --rm webserver createsuperuser
Das war es. Über das Webinterface kann man sich nun einloggen:
http://server:8000
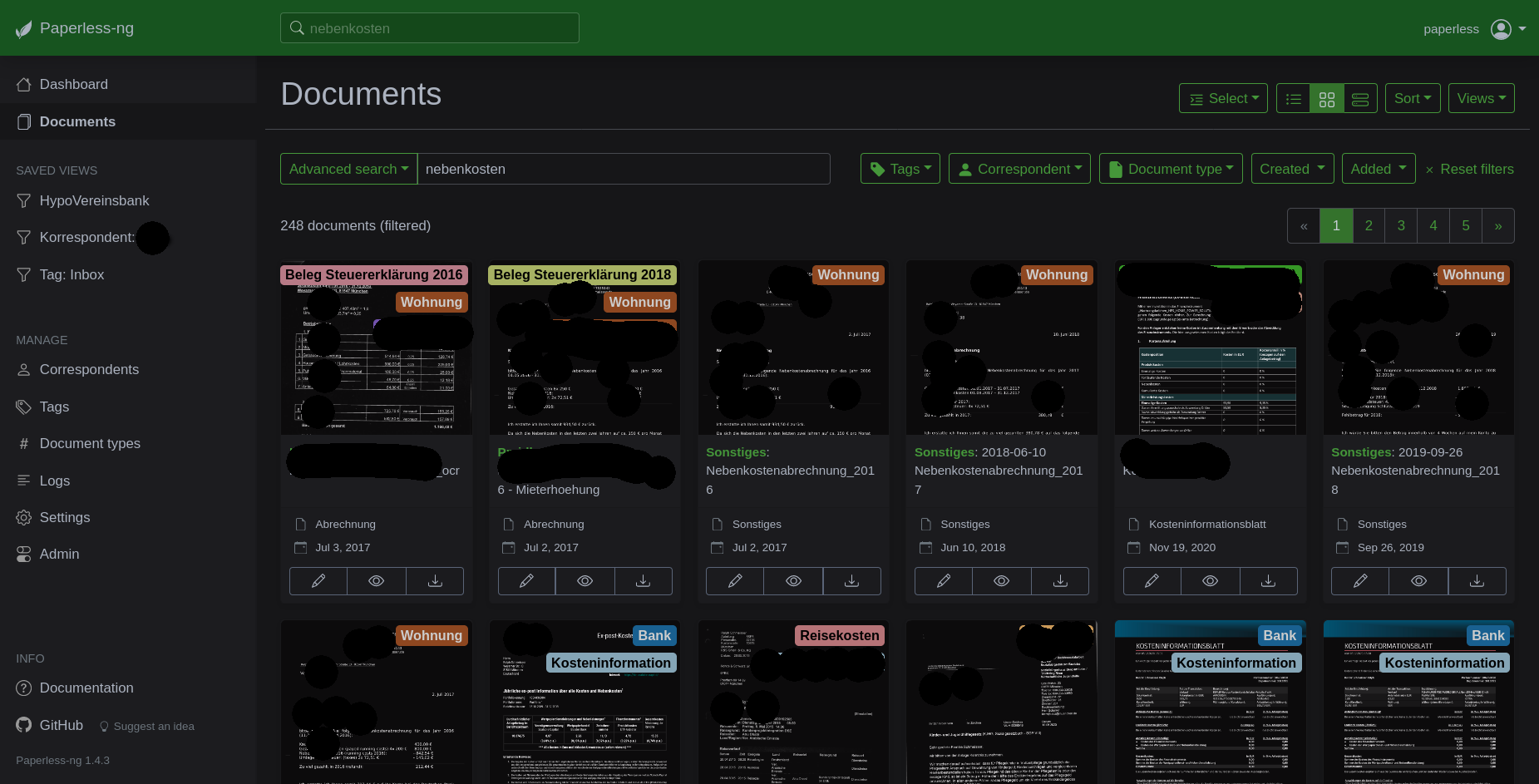
Dokumente hochladen
Wie kommen nun die Dokumente ins Dokumentenmanagement-System? Hier bietet Paperless-ng mehrere Möglichkeiten.
Webinterface
Die naheliegendste Variante ist über das Webinterface. Einloggen und entweder über den "Browse Files"-Button oder auch einfach per Drag and Drop. Fertig.
Android App
Ist man per Smartphone unterwegs - Verbindung zum Heimnetz vorausgesetzt - besteht die Möglichkeit, die Android App "Paperless" aus dem F-Droid Store zu verwenden. Mit dieser kann über den Teilen Button in Android ein Dokument an den Paperless-Server gesendet werden. Gerade wenn man, wie ich, nur noch viel mit dem Smartphone unterwegs ist, ist dies ziemlich praktisch. Der Umweg über das Notebook oder den Desktop Rechner entfällt somit.
Zum Verwalten und Finden der Daten, finde ich wiederum das Webinterface auch auf dem Smartphone die beste Option.
consume-Ordner
Damit man sich auch am PC den Umweg über das Webinterface sparen kann, gibt es bei Paperless-ng den consume Ordner. Man legt also einfach die Dokumente dort hinein und Paperless-ng verarbeitet diese automatisch.
Der Ordner lässt sich im docker-compose.yml konfigurieren:
...
volumes:
...
- /home/myfunkyuser/consume:/usr/src/paperless/consume
...
Und schon hat man im Home-Verzeichnis den Ordner "consume", in welchen man nun einfach noch die PDF-Dateien kopiert.
Allerdings läuft der Docker Container bei den meisten Nutzern vermutlich wie auch bei mir, nicht auf dem Arbeitsplatzrechner, sondern auf einem kleinen Home-Server oder Raspi.
So ziemlich alle Dateimanager unter Linux beherrschen es per SSH auf einen Ordner zuzugreifen. Also einfach ssh://192.168.2.3 im Dateimanager eingeben, die User und Passwort-Abfrage beantworten und fertig. Zum einfacheren Zugreifen, kann man diesen SSH-Ordner auch in den Links oder Favoriten speichern oder ihn über die FSTAB mounten.
E-Mail / IMAP Collector
Als vierten Weg bietet Paperless-ng auch noch einen E-Mail Collector. Paperless-ng kann also automatisch die Mailbox nach E-Mails mit PDF-Dateien durchforsten und diese verarbeiten. Eingerichtet wird dies über das Webinterface im Bereich "Admin".
Eine Beschreibung, wie dies konfiguriert werden kann, ist hier zu finden: Dokumentation Paperless-ng IMAP.
Es landen also z. B. alle Rechnungen, die per E-Mail ankommen, automatisch in der Dokumentenverwaltung. Sehr praktisch. Theoretisch. Denn alle meine Mails, die ich erhalte, sind verschlüsselt. Entweder direkt vom Absender oder spätestens mit der Inbox-Verschlüsselung von Mailbox.org. Mit verschlüsselten Mails kann Paperless-ng leider noch nicht umgehen.
Dokumentenmanagement
Aber was macht Paperless-ng nun eigentlich mit einem PDF? (Randbemerkung: Paperless-ng kann nicht nur mit PDFs umgehen, sondern prinzipiell auch mit .doc und anderen Office-Formaten. Allerdings wird dies von mir nicht genutzt.)
Der grundlegende Workflow ist einfach:
- Dokument hochladen
- OCR (Texterkennung)
- Ablegen des Original-Dokumentes
- Ablegen des Dokuments mit OCR
- Anreichern von Meta-Daten, wie Tags, Datum, Korrespondent & Co.
- Suchfunktion
Die Meta-Daten
Paperless-ng ordnet jedem Dokument die folgenden Meta-Daten zu:
-
Title: Der Titel des Dokuments. Dieser wird aus dem Dateinamen des Dokuments übernommen.
-
Archive serial number (ASN): Möchte man eine eindeutige Zuordnung vom Papierdokument, welches man in einem Ordner aufhebt, kann man eine ASN vergeben. Dies ist eine einfache fortlaufende Nummer, welche auf dem Papierdokument und in den Meta-Daten angegeben wird. So lässt sich das Original-Dokument in einem Ordner schnell finden.
-
Date created: Das Datum des Dokuments. Dieses wird automatisch aus dem Inhalt des Dokuments ermittelt.
-
Correspondent: Der meiner Meinung nach neben dem Datum die wichtigste Meta-Information. Die Zuordnung des Korrespondenten. Also z. B. Sparkasse Düsseldorf, Hausverwaltung Mayr.
-
Document type: Die Art von Dokument. Also z.B. Kontoauszug, Rechnung, Vertrag
-
Tags: Frei definierbare Tags, welche das Dokument zuordnen sollen. Also z.B. Wohnung, Auto, Depot, Bank, Beleg Steuererklärung 2019
-
Content: Der per OCR erfasste Inhalt, welcher vor allem für die Volltextsuche relevant ist.
Anlegen von Meta-Daten
Damit nun die hochgeladenen Dokumente mit den Meta-Daten versehen werden können, legen wir diese zunächst an. Im Webinterface können im Bereich "Manage", die "Correspondents", "Tags" und "Document types" einfach angelegt werden.
Beim Anlegen der Meta-Informationen muss auch immer ein "Matching algorithm" ausgewählt werden. Dazu gleich mehr.
Sind also die Tags (Bank, Wohnung, Auto), die Korrespondenten (Hausverwaltung Mayr, Sparkasse Düsseldorf) und die Dokumententypen (Vertrag, Angebot, Rechnung) angelegt, kann man die Dokumente damit ausstatten.
Klingt erst mal nach viel händischer Arbeit pro Dokument.
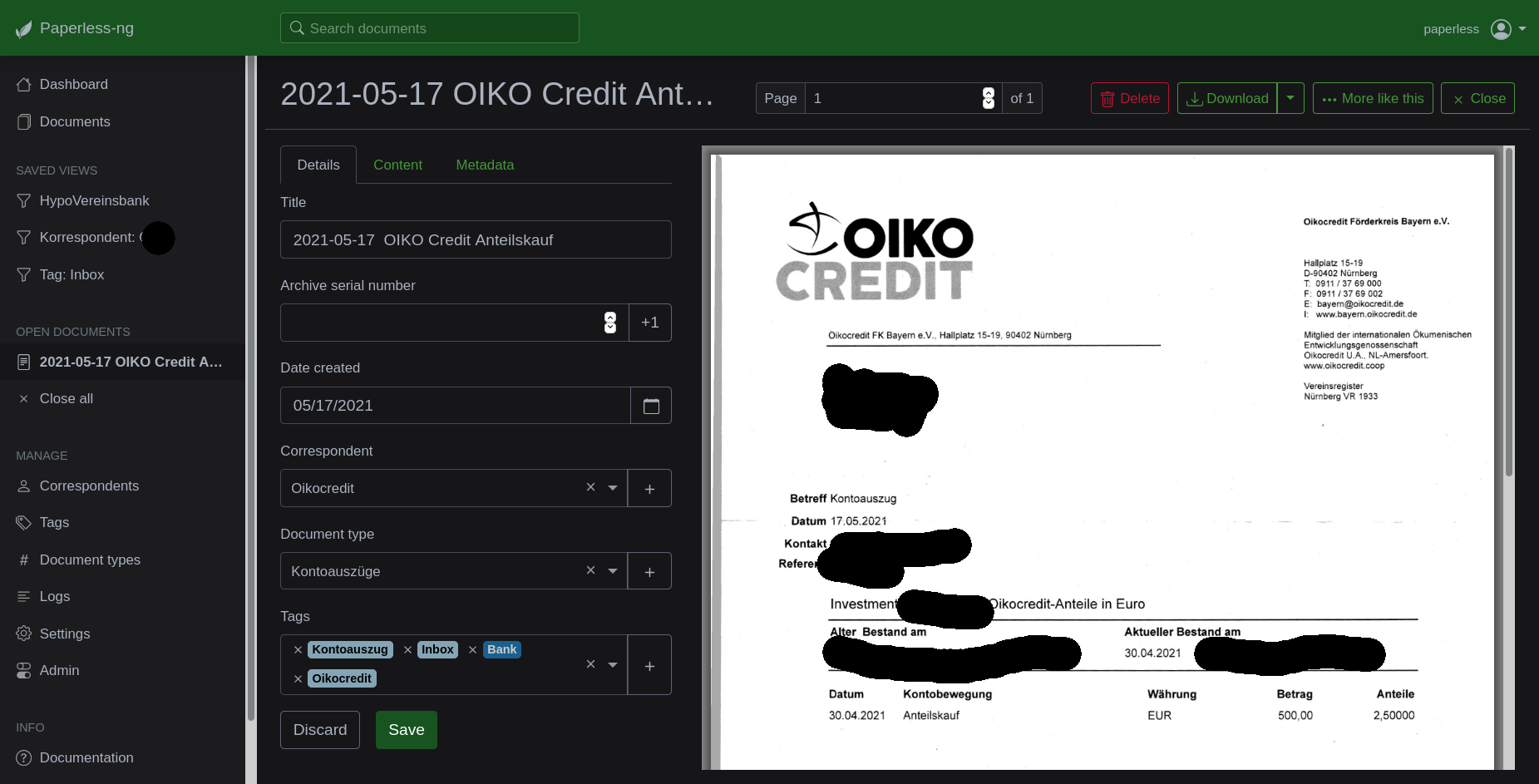
Matching
Aber hier kommt genau das Matching ins Spiel. Die Zuordnung von Tags, Korrespondenten und Dokumententypen zu den Dokumenten soll natürlich nicht immer händisch passieren, sondern Paperless-ng soll uns die Arbeit abnehmen.
Hierfür bietet Paperless-ng mehrere Methoden an. So kann z. B. der Algorithmus "Exact" verwendet werden. Kommt nun das Wort "Sparkasse Düsseldorf" genau in dieser Schreibweise in einem Dokument vor, dann wird der Korrespondent "Sparkasse Düsseldorf" dem Dokument zugeordnet.
Nicht immer ist es ganz einfach, Matching-Regeln zu definieren. Nicht immer kommt "Sparkasse Düsseldorf" direkt hintereinander. Manchmal wird das "ü" beim OCR nicht richtig erkannt und es heißt Sparkasse Dusseldorf". Hier kommt nun das neuronale Netz von Paperless-ng ins Spiel. Dies ist die eigentliche Stärke der Software. Wählt man als Matching Algoritmus "Auto: Learn matching automatically", ordnet Paperless-ng alle Meta-Daten automatisch den neuen Dokumenten hinzu. Dabei lernt das neuronale Netzwerk mit jedem weiteren Dokument hinzu und das Matching wird immer besser.
Anfangs ist dies noch ein wenig frustrierend. Aber hat man die ersten 50 unterschiedlichen Dokumente in Paperless-ng verwaltet, wird das automatische Matching sehr zuverlässig. Bei mir sind es nun mittlerweile ca. 4000 Dokumente in Paperless-ng und das neuronale Netzwerk funktioniert bei wiederkehrenden Dokumenten mittlerweile so gut, dass nur selten Nacharbeit notwendig ist.
Statische Regeln haben einen Nachteil. Legt man z. B. fest, dass jedes Dokument mit dem Inhalt "Steuerberaterin Musterfrau" den Korrespondenten "Musterfrau" bekommt, funktioniert dies für viele Dokumente. Allerdings wird z. B. auch ein Kontoauszug der Sparkasse dem Korrespondenten "Musterfrau" Zugwiesen, wenn dieser eine Überweisung an "Musterfrau" enthält. Bei der Nutzung des neuronalen Netzwerks stehen die Chancen nicht schlecht, dass der Kontoauszug der Sparkasse zugewiesen wird.
Ich nutze selbst nur die "Auto"-Funktion als Zuordnungsmechanismus.
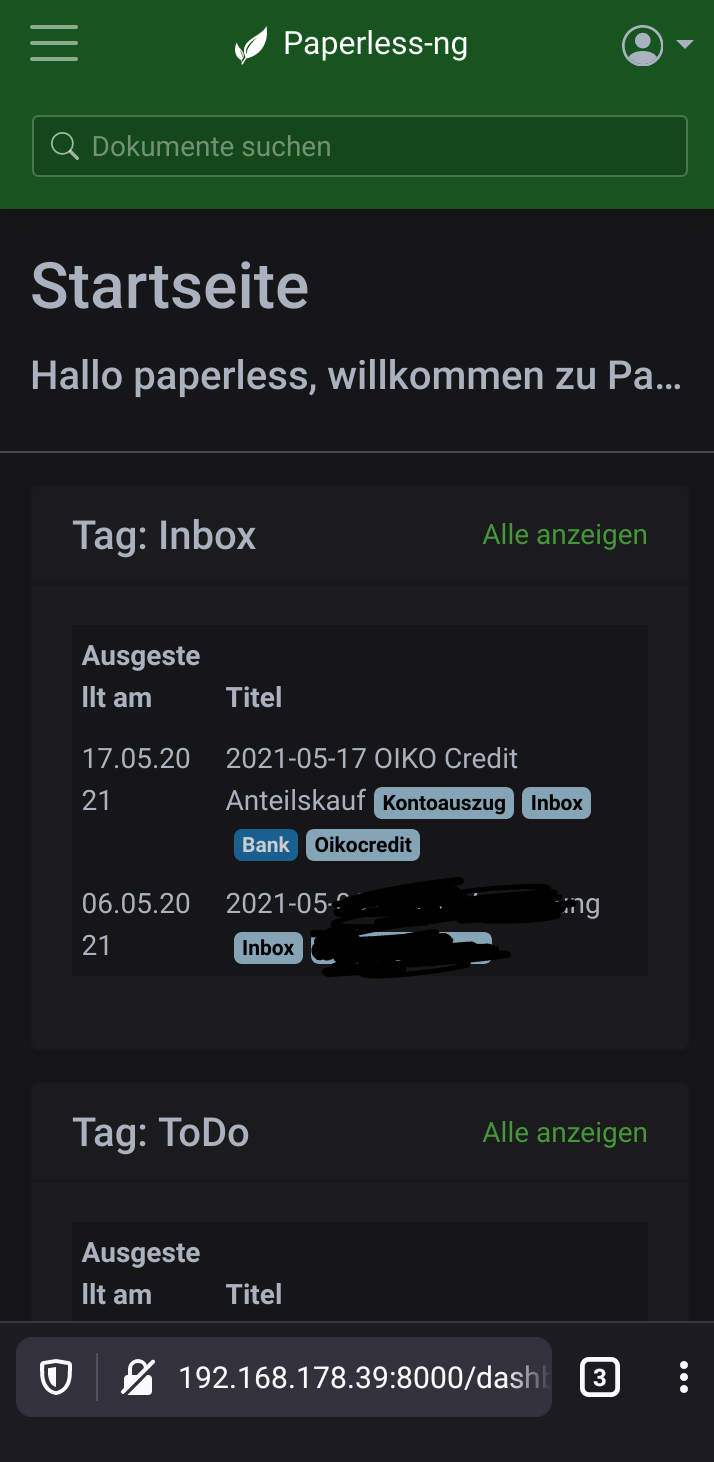
Inbox Tag
So weit also alles klar. Wir laden Dokumente in die Dokumentenverwaltung und es werden automatisch die Meta-Daten zugeordnet. Ein wenig händische Arbeit bleibt aber doch noch: Prüfen, ob Paperless-ng wirklich die korrekten Tags, Korrespondenten & Co zugeordnet hat.
Beim Anlegen der Tags ist uns schon die Checkbox "Inbox-Tag" aufgefallen. Diese Checkbox sollte bei einem Tag gesetzt werden. Ist die Checkbox aktiv, wird immer jedem neu hinzugefügten Dokument dieser Tag angehängt. Einfachhalber nutzen wir den Tag "Inbox" und wählen dort "Inbox-Tag" aus.
Was bringt uns das? Wir können alle Dokumente mit dem "Inbox" Tag auf Korrektheit prüfen und anschließend den Tag entfernen. Er dient uns also als Vorfilter. Ziemlich raffiniert.
Dokumente finden
Paperless-ng hat im Webinterface eine Suche integriert. Diese durchsucht sowohl den Inhalt der Dokumente und bietet auch die Möglichkeit, die Suche über weitere Meta-Daten einzuschränken.
z.B. "correspondent:HypoVereinsbank Tierpark"
Am häufigsten wird man die einfache Volltextsuche verwenden. Sollte dies zu viele Treffer finden, lässt sich die Suche im Anschluss die Suche noch über die Tags, Korrespondenten usw. einschränken.
Backup
Der Autor der Software hat auch dem Thema Backup in der Dokumentation ein eigenes Kapitel spendiert: Dokumentation
Hilfreich: Die PDF-Daten liegen im Klartext im Backup. Im Worst Case kann man also auf jeden Fall auf die Daten zugreifen. Auch ohne dass die Software läuft.
Mit folgendem Mini-Script erzeuge ich mein Backup:
docker-compose -f /root/paperless-ng/docker-compose.yml down
tar cfv /home/user/backup/$(date -I)_backup_paperless_media_$(date -I).tar /var/lib/docker/volumes/paperlessng_media
tar cfv /home/user/backup/$(date -I)_backup_paperless_data_$(date -I).tar /var/lib/docker/volumes/paperlessng_data
tar cfv /home/user/backup/$(date -I)_backup_paperless_pgdata_$(date -I).tar /var/lib/docker/volumes/paperlessng_pgdata
docker-compose -f /root/paperless-ng/docker-compose.yml up -d
Folgende drei Archiv-Dateien sind das Ergebnis:
-
paperless_media: Alle Dateien in der Original-Version (originals) und in der Version mit OCR-Schicht (archive). Die Original-Versionen sichere ich monatlich unverschlüsselt auf eine DVD. So kann im Fall der Fälle auch jemand ohne tiefe technische Kenntnisse auf meine Dokumente zugreifen.
-
paperless_data: Die Meta-Daten
-
paperless_pgdata: Die SQL-Datenbank
Nach einem Crash ist somit ein Restore kinderleicht.
Update
Ein Update ist dank der Container-Technologie einfach:
docker-compose pull
docker-compose down
docker-compose up -d
Fertig. Die neue Version läuft.
Finetuning
Tag-Empfehlungen:
-
Es macht keinen Sinn, dass Tags und Korrespondenten Duplikate sind. Also gibt es "Deutsche Telekom" und "O2" nur als Korrespondent. "Handy Vertrag" gibt es dafür als Tag.
-
Nicht für jeden Korrespondenten und jeden Dokumententyp macht es Sinn, diesen in Paperless-ng anzulegen. Einen Korrespondenten und einen Dokumententyp "Sonstiges" zu haben, wenn man sehr wahrscheinlich nicht viele dieser Dokumente haben wird, ist also durchaus legitim.
-
Mit der Anzahl der Tags sollte man es nicht übertreiben, da es hier sonst unübersichtlich werden kann. Hat man vorher mit einer Ordnerstruktur gearbeitet, kann man sich an dieser orientieren.
Anpassung Datumsformat
Ignore Dates
PAPERLESS_IGNORE_DATES="1954-02-16"
Paperless-ng findet automatisch das korrekte Datum anhand des Inhalts eines Dokuments. Aktuell wird dafür das erste gefundene Datum verwendet. Dies kann jedoch z. B. auch gerne mal das eigene Geburtsdatum sein. Entsprechend kann man Paperless-ng, wenn man die angegebene Option im docker-compose.env angibt, beibringen, das jeweilige Datum zu ignorieren.
Datum aus Dateinamen
Scanne ich Dokumente, dann erfasse ich im Dateinamen immer das schon das jeweilige Datum im Format YYYY-MM-DD. Also z. B. 2021-04-13. Paperless-ng versucht normalerweise das Datum nur aus dem Inhalt des Dokument zu ermitteln. Der Dateiname wird ignoriert. Mit folgender Option prüft Paperless-ng zunächst den Dateinamen auf ein gültiges Datum:
PAPERLESS_FILENAME_DATE_ORDER=YMD
Gerade wenn man vorher mit einer Ordnerstruktur gearbeitet hat und seine Dateien immer sauber benannt hat, ist diese Option sehr hilfreich.
Delete Duplicates
Paperless-ng prüft vor jedem Import per Checksumme, ob ein Dokument ein Duplikat ist. Ist dies der Fall, wird es nicht importiert. Verwendet man den consume-Ordner wird also die Datei im Ordner belassen und nicht angefasst. Dies führt in der Praxis gerne mal dazu, dass man sich wundert, warum die Datei so lange im Consume-Ordner liegt. Erst ein Blick ins Logfile oder auf die Webseite schafft dann Klarheit.
Gibt man die folgende Option an, dann löscht Paperless-ng Duplikate aus dem Consume-Ordner und erspart einem somit ein wenig Arbeit:
PAPERLESS_CONSUMER_DELETE_DUPLICATES=true
Recursive Consume Folder
PAPERLESS_CONSUMER_RECURSIVE=true
Dateien in Unterordnern des consume-Ordners werden von Paperless-ng standardmäßig ignoriert. Mit der oben genannten Option, werden auch Dateien aus Unterordnen erfasst.
Fazit
Paperless-ng läuft bei mir nun seit Anfang 2021 und verwaltet seitdem alle neu hinzugekommenen Dokumente. Auch alle meine bisherigen Dokumente habe ich erfasst. So komme ich nun mittlerweile auf nahezu 4000 Einzeldokumente.
Paperless-ng macht die Verwaltung von Dokumenten nicht sexy, aber erträglich. Die Software ist gut gepflegt, bekommt häufig Bugfixes und neue Features und läuft stabil. Die Pflege, Backup & Co ist Dank Containern sehr einfach und wenig Zeitaufwändig. Die Zuordnung von Tags, Korrespondenten und Dokumententypen funktioniert, sowohl über das neuronale Netzwerk oder alternativ auch über klassische Regex-Lösungen, sehr gut.
Für mich hat Paperless-ng meine bisherige Ordnerstruktur vollständig abgelöst. Alle Dokumente sind nun zentral verwaltet und gepflegt. Über den Monat verteilt werfe ich alle anfallenden Dokumente in den consume-Ordner oder lade sie über die App in Paperless-ng hoch. Einmal pro Monat wird dann die Zuordnung der Tags und Korrespondenten überprüft. Fertig.
Dank & Feedback
Titel-Photo by Photo by Susan Q Yin on Unsplash
Ich freue mich über Feedback. Hinterlasst hier einen Kommentar oder Stern oder schreibt mir gerne per Mastodon.

Comments
No comments yet. Be the first to react!